Mapping template
A mapping template is only necessary with the Omni ConnectorIf you are using another catalog connector, you can proceed with developing your transformation templates.
Once a connector receives your raw catalog data, it begins to transform that data into a format Constructor can ingest. To do that, the Connect CLI will first feed the catalog data through a mapping template.
A mapping template plays a crucial role in the data transformation process as it takes a catalog file (JSONL), identifies theitems, variations, and item groups data, and feeds that data into the corresponding transformation templates.
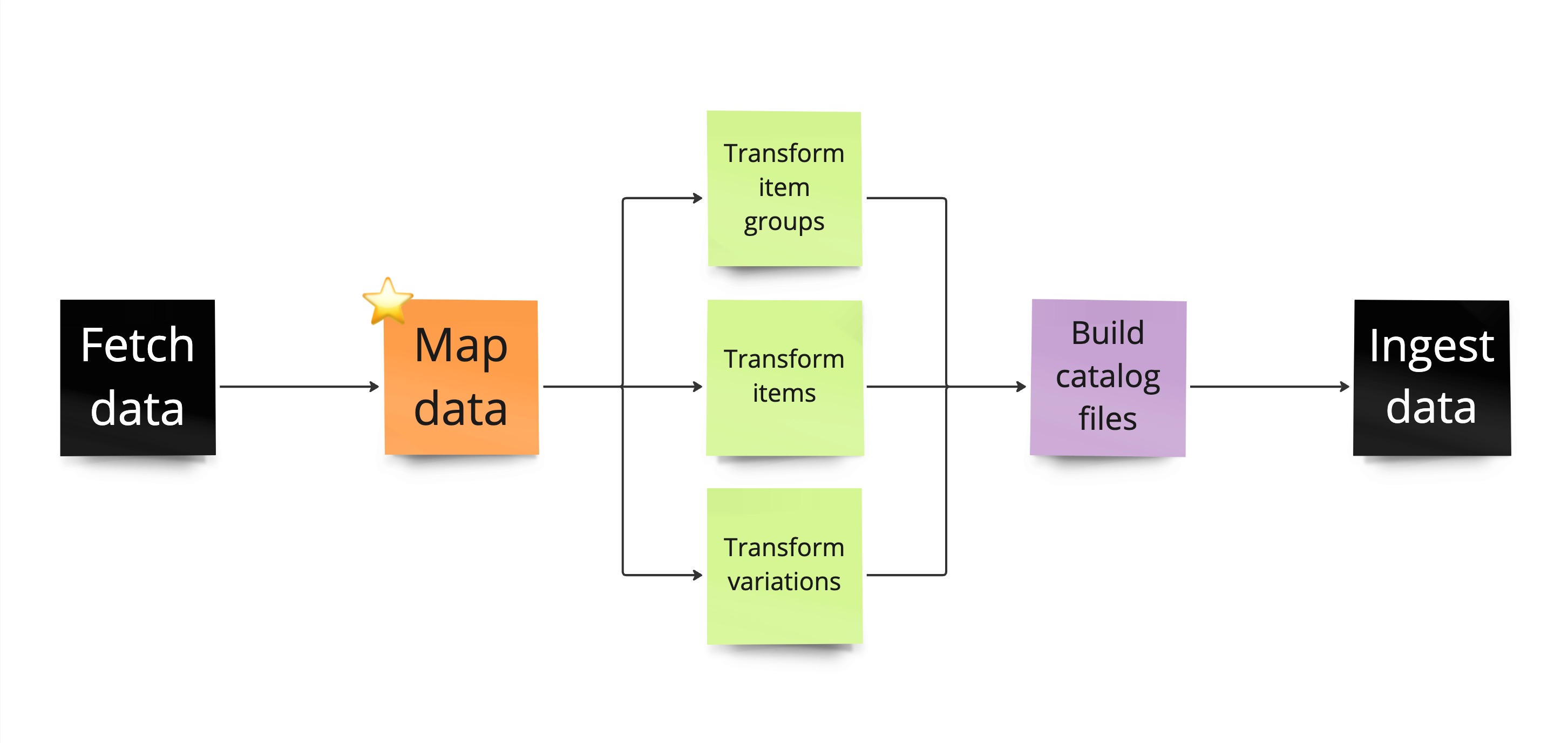
The data transformation process
Do I need a mapping template?
If you are using theOmni Connector to ingest your catalog data, then you will need to develop a mapping template. It is a necessary step that allows the connector to understand the structure of your raw catalog data before transforming it into items, variations, and item groups.
However, if you are using a partner connector (for example, Shopify, Salesforce, etc), then you do not need a mapping template as the Constructor Connector already knows the file structure for these platforms.
How do I develop a mapping template?
Keep in mind that the mapping template will map your raw file data—whatever that is—to sanitized data that can be transformed into items, variations, and item groups.
Because of this, mapping templates are highly dependent on which data you are sending to the connector.
Prerequisites
To develop a mapping template, you will need:
- Your catalog data. This is the file you'll send to the Omni Connector. For example, a JSONL file sent via SFTP. Please ensure the file is properly structured.
- A fixture. This allows the CLI to pipe the data through the corresponding template. Learn how to generate fixtures here.
Develop a mapping template
Follow the development flow to develop and test a mapping template.
First, generate the mapping fixture. This is essentially a JSON file containing your catalog data. Keep in mind that the mapping template can return any number of items, variations, and item groups.
{
"items": [],
"variations": [],
"item_groups": []
}The end goal is to develop a template that will take the catalog data and only return the data necessary to populate your item, variations, and item groups fixtures.
As always, you can execute your template against the mapping fixture to confirm the mapping is correct and resolve any necessary errors.
Once you are happy with how your template looks, you can execute it and create automated tests to ensure it works properly. Finally, when you are satisfied with your template, you can deploy it.
Need more information on developing a mapping template?Please refer to the
README.mdfile within your Connect CLI repository for more details and examples on developing a mapping template.
Add unique identifiers
We encourage you to add an __id field to all entities you return with a mapping template. This ensures that the connector will be able to de-duplicate any data that ends up being repeated, so your ingestions do not fail. The connector may also apply performance improvements based on the unique identifiers.
For example, if you are mapping one item (regardless of the fixture data):
{
"items": [
{
"__id": "item_id",
"title": "My product"
}
]
}Map variations
When mapping variations, you have two options depending on how your data is structured:
- Directly return variations under
variations. Here you would return an array of variations directly from the mapping template. The connector will group them together into items before the transformation phase.- ❗With this approach, variations must have a
__parent_idproperty pointing to their parent item id. Otherwise the connector will not group them into items.
- ❗With this approach, variations must have a
- Return variations under
items. Here you would return all variations under a__variationsproperty within each item. This ensures variations are already grouped, removing the need for the connector to pre-group them before the transformation phase.- 💡 Depending on your approach, this can increase the performance of your data ingestions.
Map your data
As a simple example, say a given product from your catalog data looks like this:
{
"id": "1",
"name": "T-shirt",
"categories": ["Clothes", "Shirts"],
"variations": [
{ "id": "1-red", "color": "red" },
{ "id": "1-blue", "color": "blue" }
]
}Since variations are already nested into each item, we can leverage the __variations field. For item groups, we will build them entirely based on the categories field.
Your mapping template could be shaped like this:
{
"item_groups": $map(data.categories, function($category, $i) {
{
"__id": $kebabCase($category),
"name": $category,
"parent_id": $i = 0 ? "" : data.categories[$i - 1]
}
}),
"items": $merge([data, {
"__id": data.id,
"__variations": data.variations
}])
}The result of your mapping would look like this:
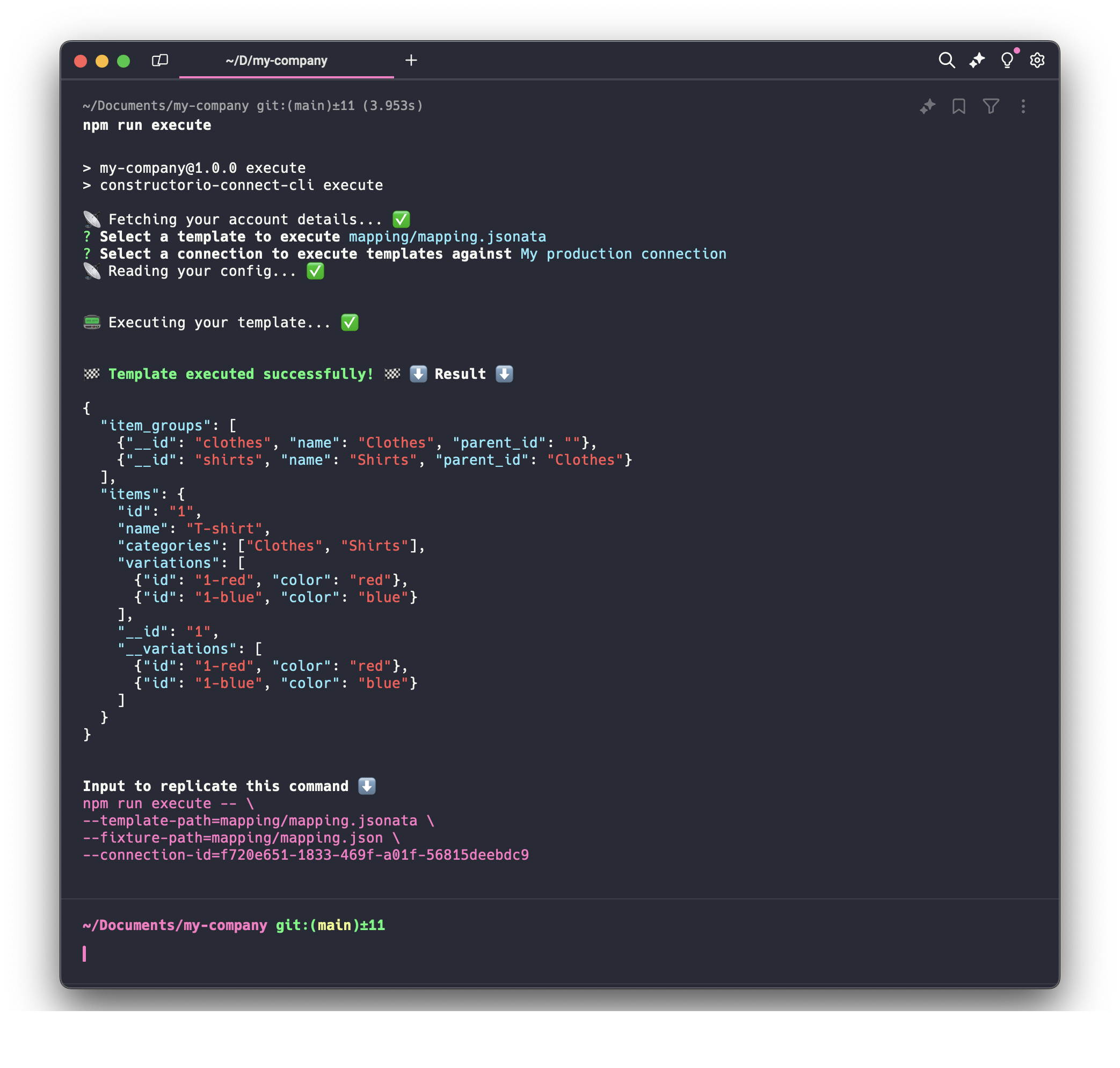
The mapping template result